Parquet Delivery for SafeGraph Data
SafeGraph now offers delivery in Parquet format for our Places and Parking Lots products.
What is Parquet?
Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. It is well-suited for handling analytic workflows with complex, nested data and offers file size and query speed advantages over CSV.
Unlike CSV, Parquet is typed, meaning the data files themselves have knowledge of the data types (including complex or nested data types) for each column. CSV is not typed, so all columns must be read in as strings and then transformed into the correct data types during the ETL process.
Examples:
postal_codecolumn : in the US, thepostal_codecolumn in SafeGraph Places corresponds to ZIP codes, which are composed of strings of five integers. Many ZIP codes have leading 0s (e.g. ZIP codes in New Jersey).- When reading in a CSV file with a column of ZIP codes, some data loading tools may ingest this column as an integer type rather than a string type. Doing so would cause leading zeros to be dropped, meaning New Jersey ZIP codes would have only four digits rather than five.
- The Parquet format does not have this problem, as the data file itself knows the
postal_codecolumn is a string type, and therefore leading zeros would be preserved.
open_hourscolumn : Theopen_hourscolumn in SafeGraph Places is a complex, nested JSON string (e.g., { "Mon": [["7:00", "9:00"], ["17:00", "21:00"]], [...], "Sun": [["8:00", "10:00"], ["17:00", "21:00"]] })- A data engineer ingesting a CSV file with this column needs to transform the flat string into the complex, nested JSON type. This is necessary to support a query such as “What restaurants are open on Mondays?”
- The Parquet file treats this column as a struct type, so no such transformation would be necessary.
More information on the Parquet format and its benefits can be found here.
FAQ
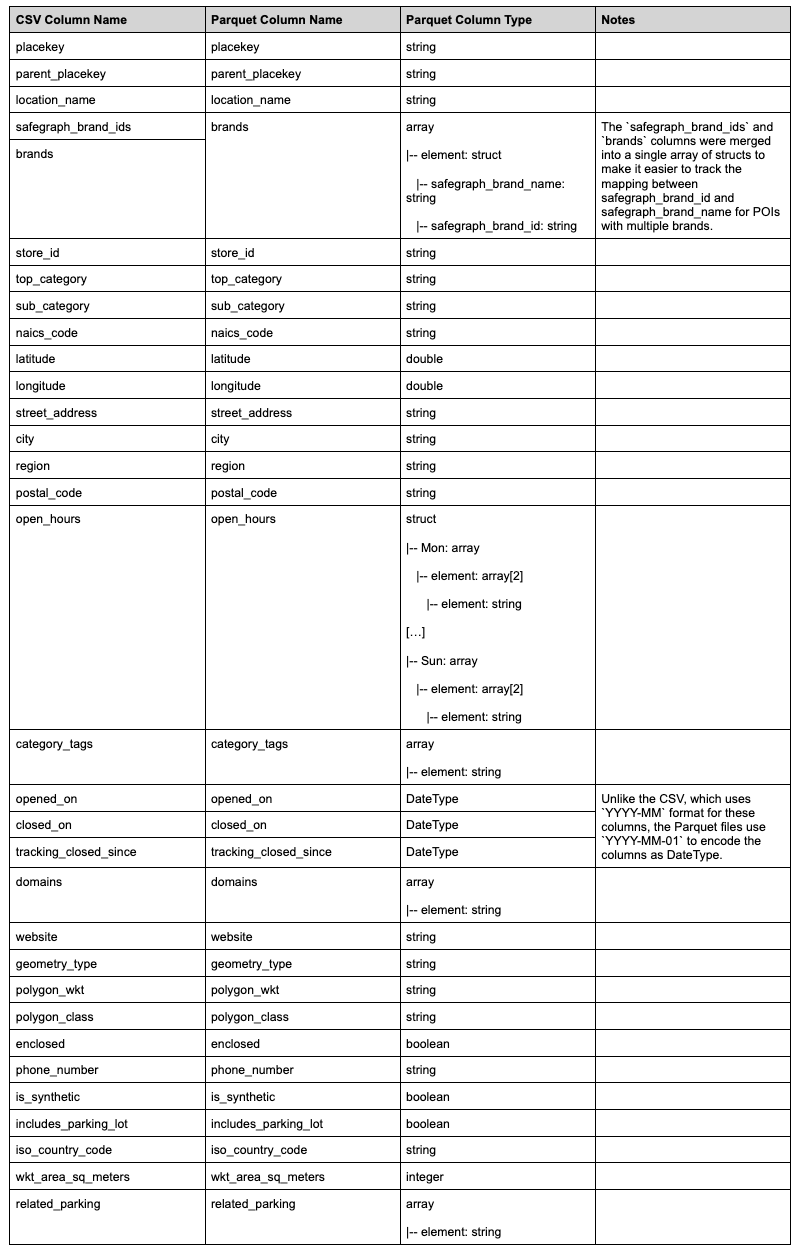
Q: Is the column schema (i.e. column names and ordering) for the Parquet files identical to the CSV files?
A: No, there are slight changes to the schemas. For instance, the closed_on and opened_on columns in the CSV files are expressed as YYYY-MM, but they are expressed as YYYY-MM-01 in the Parquet files, in order to treat these columns as DateTypes rather than strings.
A full mapping of the CSV and Parquet column schemas can be found in the Schemas section below.
Q: Will supplemental files (Places: brand_info; Spend: transaction_panel_summary) also be available in Parquet format?
A: Initially, no, these files will continue to be delivered in CSV format. It is on our near-term roadmap to provide a Parquet format delivery option for these data files as well.
Q: How will deliveries in parquet be structured?
A: If you are an enterprise customer, SafeGraph products are delivered (together) by 7th of the month, but we target the 1st if its a business day. Up to 5 file paths will be delivered with the following structure: s3://customer-bucket/customer-prefix/{{sg-file-name}}/yyyy/mm/dd/hh/*.parquet. {{sg-file-name}} is one of the following:
core_poi, geometry, spend_patterns or some combination like core_poi-geometry (depending on your subscription) includes all of the following to which you are subscribed.
Schemas
Places (incl. Geometry attributes)
Parking Lots

Updated over 1 year ago